Inferring actionable information from visual data in 3-D environments
This project aims to improve the perception and semantic understanding of 3-D environments, with the goal of aiding interactions with that environment. We have developed neural techniques that allow us to complete missing geometry, localize cameras, capture objects with high-quality textures, predict object affordances, and understand natural language references to objects in the scene.

Focus Group Visual Computing
Prof. Leonidas J. Guibas (Stanford University), Alumnus Hans Fischer Senior Fellow | Manuel Dahnert (TUM), Doctoral Candidate | Host: Prof. Matthias Nießner (TUM)
Focus Group goal and effort rationale
For both humans and autonomous robotic agents, the action of perceiving an environment and its objects typically aims at planning and execution of future actions. Traditional computer vision, however, has focused either on object recognition, where the goal is to detect and assign semantic classes to objects, or on reconstruction, where the aim is to build full 3-D models of objects. Our goal in this project has been to develop the algorithms and datasets that support object-centric actionable information extraction from visual data – that is, low-dimensional information sufficient for planning and executing actions to bring the environment into a desired state.
Our efforts have aimed to generate scene understanding that informs robotic agents operating in indoor environments as well as helping humans who, due to age, disability, or lack of skill, may need assistance in performing various tasks. This has motivated the study of natural language object references and understanding in a scene context, so as to facilitate communication between the human and an assistive agent.
The Fellowship period (2018–2022) coincided with the Covid-19 pandemic, which severely restricted international travel. Despite the reduced number of physical visits and stays, the Stanford and TUM groups maintained an active collaboration that resulted in significant progress in 3-D computer vision.
Stanford and TUM-IAS collaborative research highlights
Inspired by the above goals, our Stanford / TUM-IAS collaborative activities have focused on the following areas:
Embedding spaces for 3-D geometry
Models of 3-D shapes can come either from ab initio design or from scanning real objects. These two modalities often contain complementary information toward understanding environments. However, establishing a mapping is a challenging task due to strong, low-level differences. We learn a novel joint embedding space [1] using 3-D deep learning, where semantically similar objects from both domains lie close together, which can be exploited in retrieving designed models similar to scanned real-world objects, enabling scan denoising and completion.
Texture acquisition and generation
The creation or capture of 3-D models requires good texture modeling. Our TextureNet work [2] establishes consistent local parametrizations on meshes, making it easier to learn high-resolution signals such as textures. We also address issues in learning textures coming from misaligned images by proposing a novel adversarial loss based on a patch-based conditional discriminator that guides the texture optimization to be tolerant to such misalignments.
Camera localization and pose estimation
Acting on the objects in an environment requires accurate estimation of both agent and object pose. We introduced a novel passive-active camera localization strategy where the agent actively moves to better localize the camera [4]. We also developed a unified framework (CAPTRA) that can handle 9DoF (nine degrees of freedom) pose tracking for novel rigid object instances as well as per-part pose tracking for articulated objects from known categories.
Affordances and manipulation action prediction
We have explored the use of simulators in learning how robotic agents can interact with articulated objects. We addressed the design of networks that can extract highly localized actionable information related to elementary actions such as pushing or pulling [4]. For example, given a drawer, our network predicts that pushing anywhere on the surface of the drawer can help close it, while only applying a pulling force on the handle or drawer edge will help open it. We also extended these basic motions to longer trajectories that accomplish a specific goal and have shown how to learn articulated object affordances with a minimal number of interactions.
Figure 1
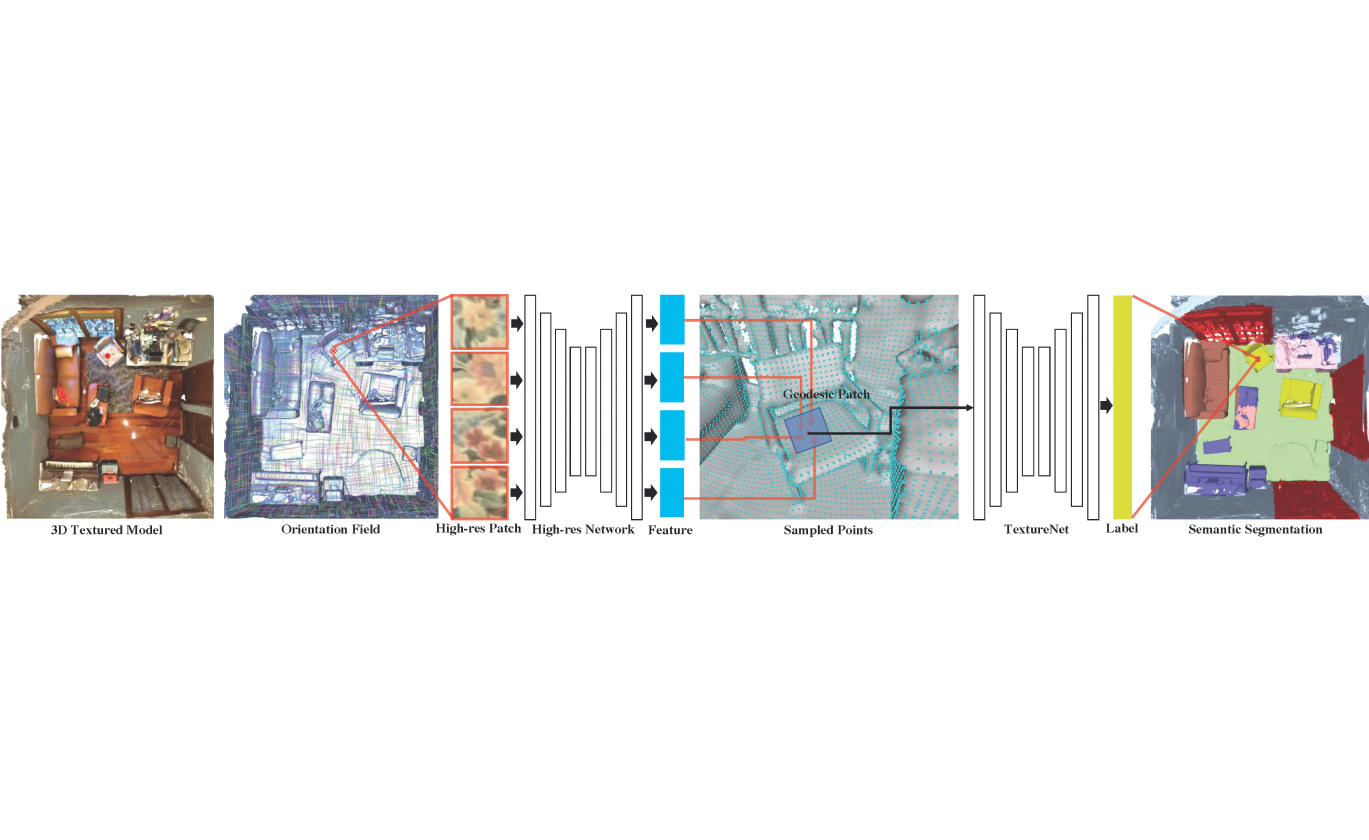
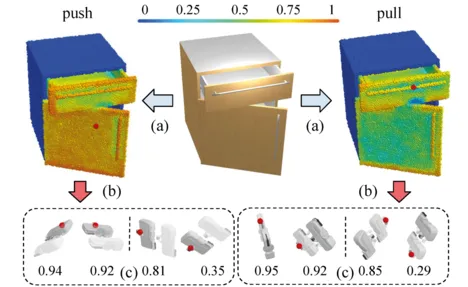
Language understanding and generation for objects in scenes
We studied the challenging problem of using referential language to identify common objects in real-world 3-D scenes, focusing on multi-instance and semantically fine-grained objects. To ameliorate to the scarcity of data for this problem, we developed two large-scale and complementary visio-linguistic datasets to demonstrate how to combine linguistic and geometric information and creating multi-modal (3-D) neural listeners that can perform fine-grained object localization and discrimination [5].
Synergistic activities
International workshop: Machine learning for 3-D understanding (TUM-IAS 2018)
With 23 invited international speakers from both academia (TUM, Imperial College, Harvard, Stanford, and others) and industry (including Google, Facebook, and Intel), the workshop covered a wide range of topics between machine learning and geometry, and it fostered an engaging atmosphere to allow for interdisciplinary exchange of ideas.
TUM-IAS doctoral candidate research stay with Prof. Leonidas Guibas’s group at Stanford (spring 2019)
In spring 2019, the TUM-IAS supported the research stay of TUM-IAS doctoral candidate Manuel Dahnert with Leonidas Guibas’s research group at Stanford University, USA, to deepen international and in-person collaboration. The goal of the stay was to develop a novel generative approach for modeling 3-D shapes using graph neural networks. The three-month stay was concluded with the presentation of another TUM-IAS project: Avetisyan et. al., Scan2CAD, at CVPR 2019, which was accepted as an oral presentation.
First workshop on language for 3-D scenes (CVPR 2021)
In 2021, our inaugural workshop on natural language and 3-D object understanding (https://language3dscenes.github.io/) at CVPR aimed to unite researchers in the field and benchmark the progress in connecting natural language with 3-D object representations of the physical world. Attended by 80 participants, it received 17 code submissions on two “language-assisted 3-D object localization” tasks. Furthermore, our underlying dataset papers (ScanRefer, ReferIt3-D) have been cited more than 70 times, since appearing at ECCV 2020, showing strong interest from the CV / CL communities.
Second workshop on language for 3-D scenes (ECCV 2022)
Following that success, we organized a second installment of the Workshop on Language for 3-D Scenes at ECCV, Tel Aviv, Israel. The program featured six international keynote speakers and the presentation of several accepted submissions of the three accompanying challenges.
Figure 3

[1]
Dahnert, M., Dai, A., Guibas, L. J. & Nießner, M (2019).
[2]
Huang, J. et al. (2019).
[3]
Fang, Q. et al. (2022).
[4]
Mo, K., Guibas, L. J., Mukadam, M., Gupta, A. & Tulsiani, S. (2021).
[5]
Achlioptas, P., Abdelreheem, A., Xia, F., Elhoseiny, M. & Guibas, L. J. (2020).
Selected publications
-
Dahnert, M., Dai, A., Guibas, L. J. & Nießner, M. Joint Embedding of 3-D Scan and CAD Objects. IEEE/CVF International Conference on Computer Vision (ICCV), 8748-8757 (2019).
-
Huang, J. et al. TextureNet: Consistent Local Parametrizations for Learning from High-Resolution Signals on Meshes. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 4435-4444 (2019).
-
Fang, Q. et al. Towards Accurate Active Camera Localization. European Conference on Computer Vision (ECCV), 122-139 (2022).
-
Mo, K., Guibas, L. J., Mukadam, M., Gupta, A. & Tulsiani, S. Where2Act: From Pixels to Actions for Articulated 3-D Objects. IEEE/CVF International Conference on Computer Vision (ICCV), 6793-6803 (2021).
-
Achlioptas, P., Abdelreheem, A., Xia, F., Elhoseiny, M. & Guibas, L. J. ReferIt3-D: Neural Listeners for Fine-Grained 3-D Object Identification in Real-World Scenes. European Conference on Computer Vision (ECCV), 422-440 (2020).