Dynamic scene understanding for autonomous agents
We work on dynamic scene understanding for autonomous agents, i.e., enabling mobile robots to understand the world around them primarily from image sensors. Our core topic is computer vision such as multi-object tracking, video panoptic segmentation, or visual localization. We also have exciting projects in the areas of brain signal analysis, image generation, and earth observation.

Focus Group Dynamic Vision and Learning
Prof. Laura Leal-Taixé (NVIDIA and TUM), Alumna Rudolf Mößbauer Tenure Track Assistant Professor | Dr. Aljosa Osep (CMU, Carnegie Mellon University), Dr. Ismail Elezi (TUM), Postdoctoral Researchers | Qunjie Zhou, Tim Meinhardt, Maxim Maximov (TUM), Doctoral Candidates
(Image: Astrid Eckert)
Since the start of the Fellowship in 2018, the Focus Group has produced a total of 52 publications in the main venues of computer vision, machine learning and robotics. I will highlight the huge advances that we have made in the three core areas multi-object tracking, visual localization, and benchmarking for video understanding in the last 4 years.
Figure 1

Multi-object tracking
Tracking-by-detection has long been the dominant paradigm for multi-object tracking, but in the last years, we have been able to propose two new paradigms that have been the dominating state-of-the-art.
We first introduced Tracktor [1] as a new tracking-by-regression paradigm, which efficiently merged the detection and the tracking tasks. We were able to train our model end-to-end by computing derivatives through tracking metrics [2].
After the success of Transformers for various image classification tasks, we were able to formulate multi-object tracking as a set prediction problem with Transformers [3], effectively presenting a new tracking-by-attention paradigm, with an unprecedented level of integration between detection and tracking.
Nonetheless, our current research is suggesting that simple tracking-by-detection trackers, if properly designed [4], can achieve even better results. Our goal for the future is to understand which parts of modern vs classic trackers are crucial to create a robust and efficient solution.
Visual localization
Deep learning is dominating almost all tasks in computer vision, and it recently started tackling the 3D domain and tasks such as visual localization as well.
In our study [5] we show the pitfalls of using machine learning for visual localization, effectively showing that current solutions are not applicable to real world scenarios. After that, we proposed several state-of-the-art solutions for visual localization based on relative pose estimation [6].
We also opened entirely new visual localization tasks, such as text to pose localization [7], which computes the exact location from a verbal description of the place.
All the above methods are based on visual features and a pre-computed map with such features stored. This has several issues, most notably: (i) privacy issues, as one can reconstruct a scene based on the visual features, and (ii) storage, as visual features take up terabytes for relatively small scenes. Therefore, we recently proposed a novel localization paradigm [8] only based on geometric features, a much harder problem, but without the privacy or storage problems. We strongly believe this will be the localization paradigm of the future.
Benchmarking for video understanding
One of the key ingredients for the success of machine learning in computer vision has been the creation of datasets with ground truth annotations, starting from the famous ImageNet. We contributed our part to the community by creating MOTChallenge [9], the now de facto benchmark for multi-object tracking.
We have enriched the benchmark in recent years with new challenges, such as temporally-dense pixel semantic annotations [10], synthetic-to-real multi-object tracking [11], and open-world tracking [12].
One of the most exciting new research lines is the study of how we can anonymize video data after recording. This is extremely important to comply with privacy laws such as GdPR. Since our multi-object tracking videos often contain hundreds of pedestrians, it is impossible to obtain express permission from everyone before filming. Therefore, we propose to modify the recorded video and replace the observed identities with synthetic counterparts. This research was started in 2020 [13] and further explored and improved in 2022 [14]. We will continue to improve the video output quality and push towards making this anonymization tool a priority for all benchmarks containing humans.
In close cooperation with: Aysim Toker, Franziska Gerken, Jenny Seidenschwarz, Andreas Roessler, Patrick Dendorfer, Guillem Brasó, Mark Weber, Orcun Cetintas (TUM), Doctoral Candidates
Figure 2
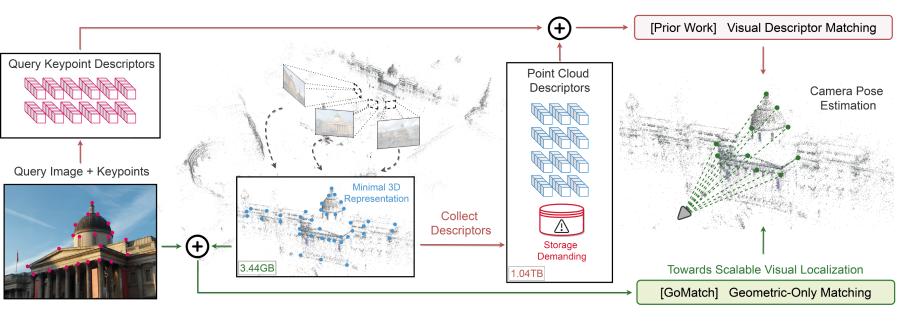
Figure 3

[1]
Bergmann, P., Meinhardt, T. & Leal-Taixe, L. (2019).
[2]
Xu, Y. et al. How To Train Your Deep Multi-Object Tracker. Conference on Computer Vision and Pattern Recognition (CVPR) (2020).
[3]
Meinhardt, T., Kirillov, A., Leal-Taixe, A. & Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
[4]
Seidenschwarz, J. et al. Simple Cues Lead to a Strong Multi-Object Tracker. Conference on Computer Vision and Pattern Recognition (CVPR) (2023).
[5]
Sattler, T., Zhou, Q., Pollefeys, M. & Leal-Taixe, L. Understanding the Limitations of CNN-based Absolute Camera Pose Regression. Conference on Computer Vision and Pattern Recognition (CVPR) (2019).
[6]
Zhou, Q., Sattler, T., Pollefeys, M. & Leal-Taixe, L. To Learn or Not to Learn: Visual Localization from Essential Matrices. IEEE International Conference on Robotics and Automation (ICRA) (2020); Zhou, Q., Sattler, T. & Leal-Taixe, L. Patch2Pix: Epipolar-Guided Pixel-Level Correspondences. Conference on Computer Vision and Pattern Recognition (CVPR) (2021).
[7]
Kolmet, M., Zhou, Q., Osep, A. & Leal-Taixe, L. Towards cross-modal pose localization from text-based position descriptions. Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
[8]
Zhou, Q., Agostinho, S., Osep, A. & Leal-Taixe, L. (2022).
[9]
Dendorfer, P. et al. (2020).
[10]
Weber, M. et al. STEP: Segmenting and Tracking Every Pixel. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (2021).
[11]
Fabbri, M. et al. MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?. International Conference on Computer Vision (ICCV) (2021).
[12]
Liu, Y. et al. Opening up Open-World Tracking. Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
[13]
Maximov, M., Elezi, I. & Leal-Taixe, L. CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks. Conference on Computer Vision and Pattern Recognition (CVPR) (2020).
[14]
Maximov, M., Elezi, I. & Leal-Taixe, L. Decoupling identity and visual quality for image and video anonymization. Asian Conference on Computer Vision (ACCV) (2022).
Selected publications
-
Bergmann, P. Meinhardt, T. & Leal-Taixe, L. Tracking without bells and whistles. IEEE International Conference on Computer Vision (ICCV) (2019).
-
Braso, G. & Leal-Taixe, L. Learning a Neural Solver for Multiple Object Tracking. Conference on Computer Vision and Pattern Recognition (CVPR) (2020).
-
Dendorfer, P. et al. MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking. International Journal of Computer Vision (IJCV) 129, 548–578 (2020).
-
Zhou, Q., Agostinho, S., Osep, A. & Leal-Taixe, L. Is Geometry Enough for Matching in Visual Localization?. European Conference on Computer Vision (ECCV) (2022).
-
Toker, A. et al. DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation. Conference on Computer Vision and Pattern Recognition (CVPR) (2022).