Grounding natural language to 3D scenes
We study the emerging research problem of connecting natural language describing objects and scenes to 3D data representations of the objects and scenes. We address resolving textual references of objects to 3D localizations of those objects, dense captioning of 3D scenes, and unified approaches that can both localize and describe objects in 3D scenes by leveraging a speaker-listener model.

Focus Group Visual Computing
Prof. Angel X. Chang (Simon Fraser University), Alumna Hans Fischer Fellow | Dave Zhenyu Chen (TUM), Doctoral Candidate | Host: Prof. Matthias Nießner (TUM)
This project is focused on connecting natural language to 3D representations of objects in real scenes. This interdisciplinary area involves methodology from natural language processing, 3D computer vision, and machine learning and is of increasing importance due to the increasing ubiquity of 3D data representing objects and scenes in the real world. With this increase of available 3D data, it is particularly important to enable the use of natural language for searching, describing, manipulating, and eventually generating 3D representations.
The project involved the investigation of a series of research problems that require connections between natural language and 3D scenes. The beginning of the project relied on recent prior work that the project team members had carried out to collect ScanNet [1]: a large-scale dataset of RGB-D scans of real scenes that was richly annotated with semantic information about the objects present in each scene. The first focus of the team was on collecting a set of natural language text descriptions of distinct objects observed in each of the ScanNet scenes. This correlated text and 3D data allowed us to address the problem of resolving references in text to objects in the 3D scan in our ScanRefer [2] paper. We found that this is a challenging research problem with much space for future work on improving 3D localization performance given natural language descriptions of objects.
In a follow up paper called Scan2Cap [3], we focused on the “inverse” direction of generating text descriptions of a given input 3D scene. Here, the focus was on generation of dense captions that refer to objects in the scene, their appearance, and spatial relations. During this work, we again observed that generation of natural language descriptions for 3D scenes is quite challenging, due to the complexity of spatial relations between objects and the diversity of objects observed in the real world.
Figure 1

Image: Chen, Z., Nießner, M. & Chang, A. X. Scan-Refer: 3D Object Localization in RGB-D Scans using Nat- ural Language. Proceedings of European Conference on Computer Vision (ECCV) (2020); Chen, Z., Wu, Q., Nießner, M. & Chang, A. X. D3Net: A Unified Speaker-Listener Architecture for 3D Dense Captioning and Visual Grounding. Proceedings of European Conference on Computer Vision (ECCV) (2022)
The third major stage in our project attempted to tackle the two previous research problems by using a unified neural architecture we called D3Net [4]. This architecture leveraged the speaker-listener methodology to enable for 3D dense captioning and grounding of natural language descriptions to 3D objects using the same architecture. A key focus of this approach was to allow the use of unannotated 3D scene data for which natural language descriptions were not available. Leveraging such data for training in a semi-supervised fashion enabled improvements in both the captioning and localization tasks. Most recently, we investigated how the more powerful transformer neural architecture can enable further improvements in the unified setting with both captioning and localization. The resulting UniT3D [5] architecture that we developed establishes state-of-the-art performance for these tasks.
In addition to the publication output referenced above, we engaged with the emerging community of researchers interested in this area of connecting language with 3D scenes through the organization of two workshops and associated benchmark challenges. The first workshop and challenge was at CVPR 2021 (virtual) and named “Language for 3D Scenes.” It involved invited talks by five research leaders in associated areas of research, as well as two benchmarks for natural language grounding tasks. The second workshop and challenge had the same title and was held at ECCV 2022 (virtual). In addition to six invited talks, we hosted a panel discussion by researchers with backgrounds in computer vision, machine learning, natural language processing, and cognitive science. We also expanded the benchmark component of the workshop by introducing a third dense captioning task. These workshops and associated challenges have helped to bring together the 3D language research community and to measure research progress in a systematic way.
The outcomes of this project can enable applications in assistive robotics, autonomous driving, and democratization of 3D content creation. All these domains and related industry sectors stand to benefit immensely from computational systems that can better understand how natural language connects with 3D data.
Figure 2
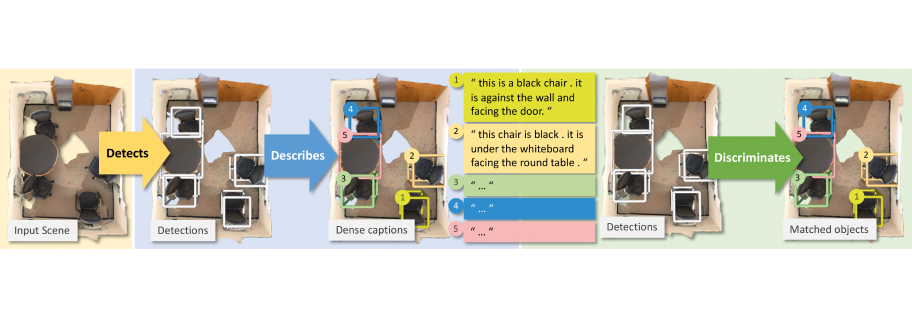
Image: Chen, Z., Nießner, M. & Chang, A. X. Scan-Refer: 3D Object Localization in RGB-D Scans using Nat- ural Language. Proceedings of European Conference on Computer Vision (ECCV) (2020); Chen, Z., Wu, Q., Nießner, M. & Chang, A. X. D3Net: A Unified Speaker-Listener Architecture for 3D Dense Captioning and Visual Grounding. Proceedings of European Conference on Computer Vision (ECCV) (2022)
[1]
Dai, A. et.al. ScanNet: Richly Annotated 3D Reconstructions of Indoor Scenes. Proceedings of the IEEE / CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2017).
[2]
Chen, Z., Nießner, M. & Chang, A. X. (2020).
[3]
Chen, Z., Gholami, A., Nießner, M. & Chang, A. X. (2021).
[4]
Chen, Z., Wu, Q., Nießner, M. & Chang, A. X. (2022).
[5]
Chen, Z., Hu, R., Chen, X., Nießner, M. & Chang, A. X. (2022).
Selected publications
-
Chen, Z., Hu, R., Chen, X., Nießner, M. & Chang, A. X. UniT3D: A Unified Transformer for 3D Dense Captioning and Visual Grounding. arXiv 2212.00836 (2022), arxiv.org/pdf/2212.00836.pdf.
-
Chen, Z., Wu, Q., Nießner, M. & Chang, A. X. D3Net: A Unified Speaker-Listener Architecture for 3D Dense Captioning and Visual Grounding. Proceedings of European Conference on Computer Vision (ECCV) (2022), arxiv.org/pdf/2112.01551.pdf.
-
Chen, Z., Gholami, A., Nießner, M. & Chang, A. X. Scan2Cap: Context-aware Dense Captioning in RGB-D Scans. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021), arxiv.org/pdf/2012.02206.pdf.
-
Chen, Z., Nießner, M. & Chang, A. X. ScanRefer: 3D Object Localization in RGB-D Scans using Natural Language. Proceedings of European Conference on Computer Vision (ECCV) (2020), arxiv.org/pdf/1912.08830.pdf.
-
Avetisyan, A. et al. Scan2CAD: Learning CAD Model Alignment in RGB-D Scans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019), arxiv.org/pdf/1811.11187.pdf.