Toward reliable and efficient neuromorphic computing
Neuromorphic computing aims to utilize very large-scale integration (VLSI) systems to mimic biological architectures, thus achieving cognitive functionalities and self-learning abilities. In the past decades, neuromorphic computing was mainly conducted at the software level, especially with neural networks.

Focus Group Neuromorphic Computing
Prof. Hai (Helen) Li (Duke University), Alumna Hans Fischer Fellow | Shuhang Zhang (TUM), Doctoral Candidate | Host: Prof. Ulf Schlichtmann, Electronic Design Automation, TUM
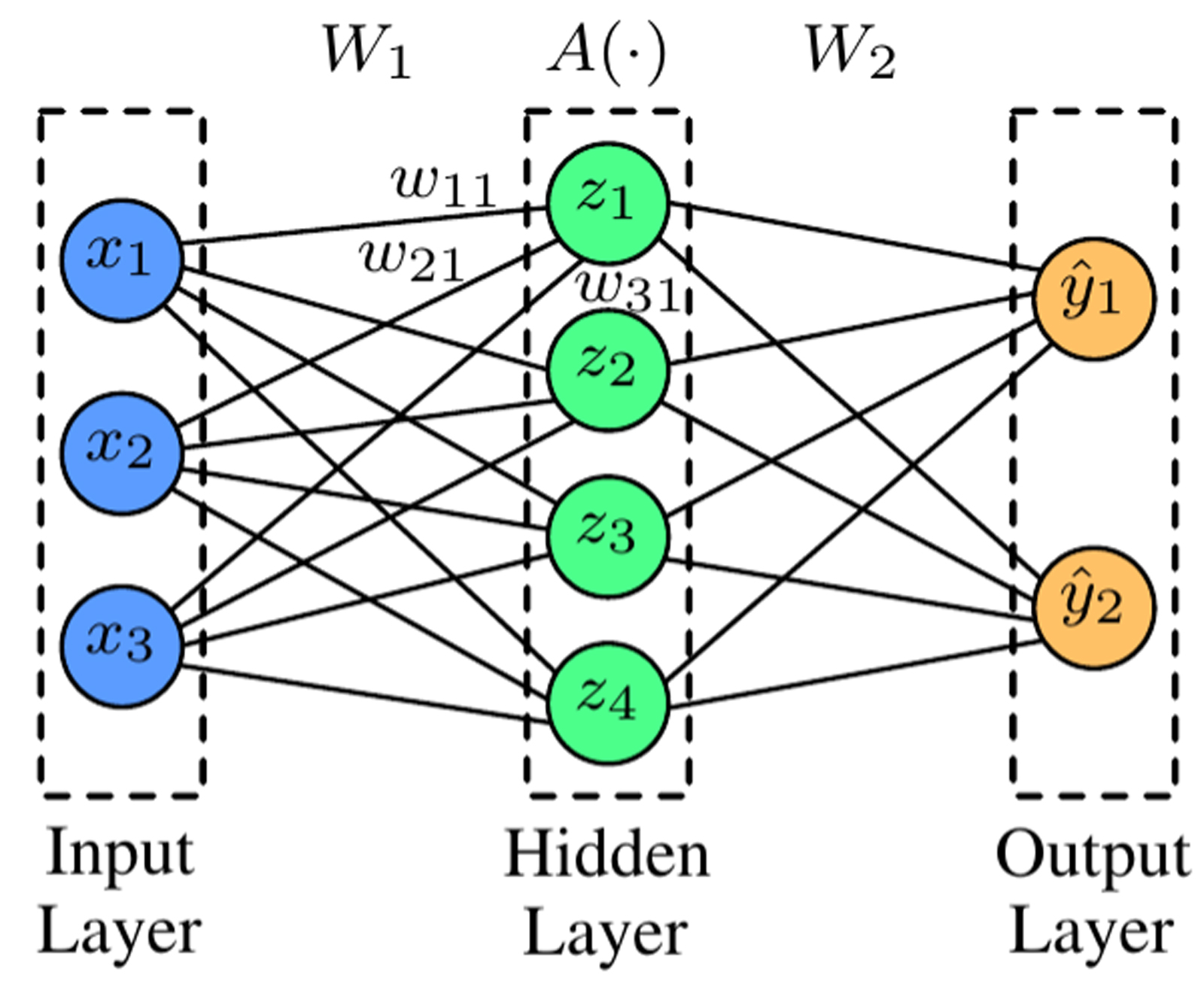
Figure 1 shows the basic structure of a neural network. The nodes represent neurons, and connections represent the relations between neurons in different layers. In a neural network, the output of a neuron is a function of the inputs and the connection weights. However, the traditional computing architecture (Von Neumann architecture) cannot support neural networks efficiently because of the processing time mismatch between CPU and memory. This phenomenon is also known as the “memory wall.” Therefore, to improve the performance of neuromorphic computing, the hardware should also be carefully reshaped.
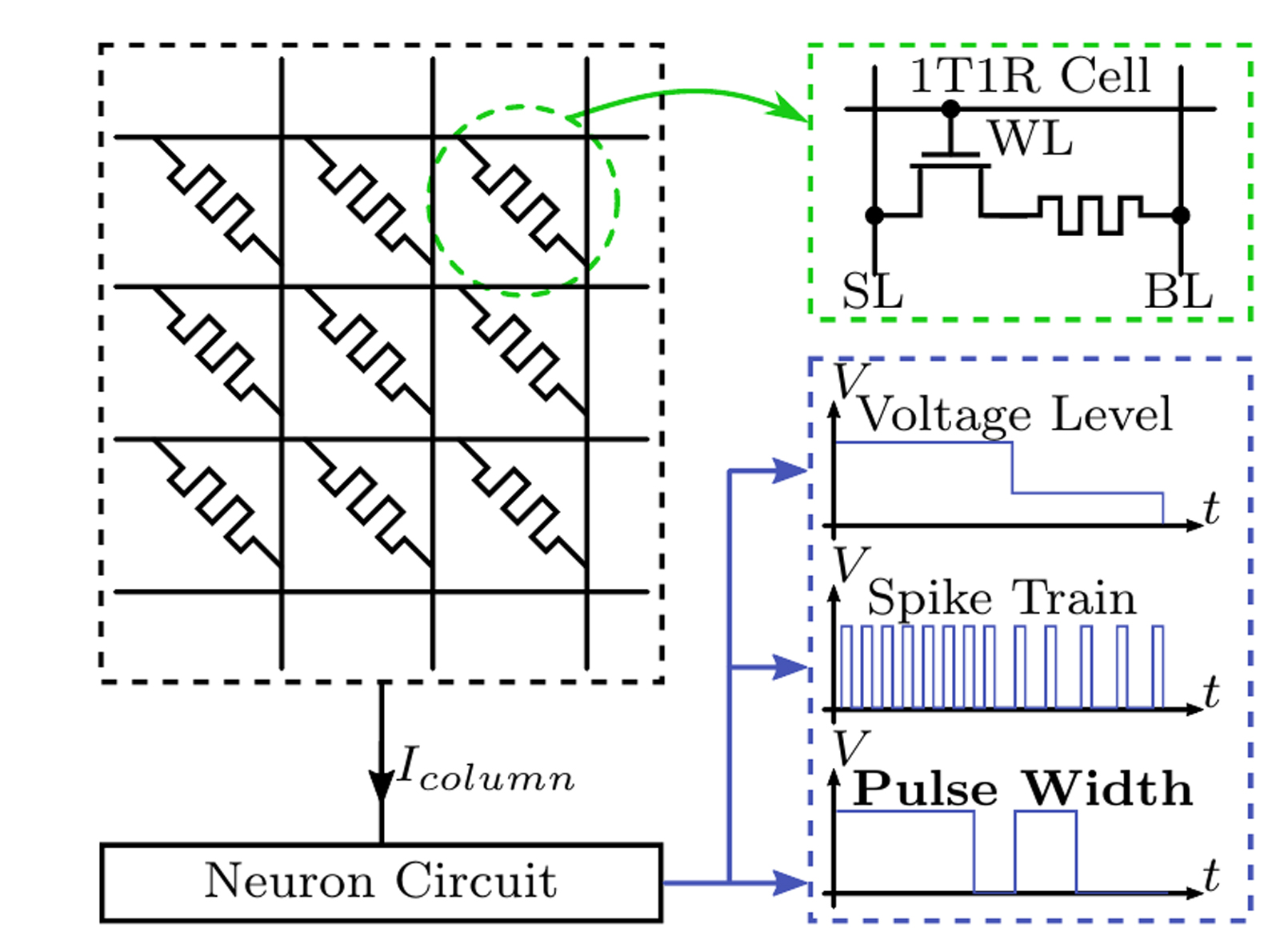
With traditional CMOS technology, it is hard to overcome the problem, but the invention of memristor technology allows us to fundamentally change the computing platform, because memristors can be used as both processing and memory units. Also, the scalability and power-efficiency of memristors make them a promising candidate for high computing density and efficiency. As shown in Figure 2, memristors sit on the crosspoints of horizontal wordlines and vertical bitlines in a crossbar structure, representing the synapses between neurons. These memristors (synapses) are programmed into different conductances to represent different neuron connections. The neuron circuits receive activations delivered by these memristors and generate voltage signals transferred to the next layer. In this way, neural networks are implemented with memristor technology.
Figure 1 and 2
We have been exploring memristor-based neural network accelerators in a bottom-up approach. First, we have focused on the reliability problem of memristor devices and proposed a software and hardware co-optimization framework. Furthermore, to improve the efficiency of signal transfer, we have designed a new neuron circuit. Finally, we have demonstrated a novel architecture based on the connection information within crossbars, which can significantly improve performance.
Like traditional CMOS devices, memristors also suffer from common reliability problems, such as aging and thermal issues. Aging affects the lifetime of manufactured devices, and the thermal issue causes unexpected results and accelerates the aging process. Therefore, we propose an effective optimization framework that counters both aging and thermal problems at both software and hardware levels. During the software training phase, we include the aging and thermal information in the cost function to average aging and thermal effects. Afterwards, we utilize a row-column swapping method to further balance the aging and thermal issues.
In neuromorphic computing, neuron circuit design is also important, and this affects computing efficiency. In the traditional neuron designs shown in Figure 2, they receive the activation from memristors, and then they generate voltage levels or spikes to the following neurons. In these formats, the transferring latency is large and requires additional processing units, leading to extra area requirements and power consumption. We have proposed a novel neuron design we call the “time neuron.” Upon receiving activation, the time neuron encodes it into a variable-width pulse, which then can be directly transferred to the following neurons.
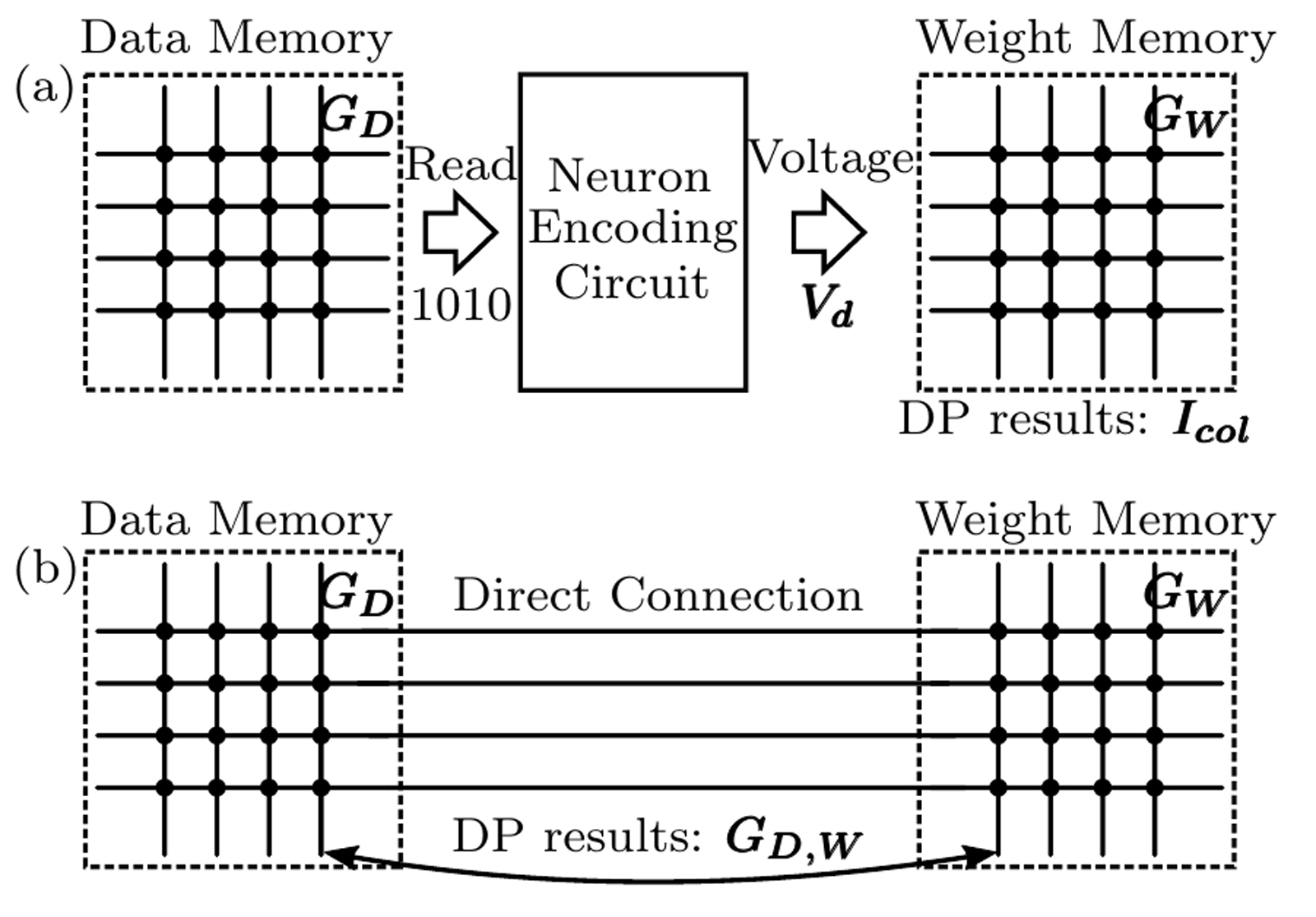
Furthermore, we have also proposed a novel computing mechanism, which is based on the connections of different data instead of the current information within crossbars, as shown in Figure 3. After writing data into crossbars, the calculation results have already been embedded in these crossbars. We then just need to read them out. In this way, we can avoid the complex computing phase used by the traditional approaches. Besides, this connection-based design can form a larger equivalent crossbar without changing the output current range, which avoids the re-design of neuron circuits.
In conclusion, we have studied neuromorphic computing intensively at different levels. Our results can improve practical applications in the real world. We hope that they will also inspire other researchers to generate new ideas. Currently, we plan to continue to explore in two different directions. The first direction is the software training algorithm for neural networks. To fully benefit from the proposed connection-based design, a specifically designed software training algorithm is necessary. The other direction for future research is applying our proposed methods and algorithms on real devices to examine their efficiency in the real world.
Figure 3