Toward more general deepfake detection through anomaly-based analysis
This project aims to develop new methods for the creation and detection of synthetic media, also known as deepfakes, with the goal of improving the ability to generalize against novel AI-generative models. The approach focuses on detecting fakes by understanding the characteristics of authentic content and identifying manipulations as anomalies deviating from the real class.

Focus Group: Visual Computing
Prof. Luisa Verdoliva (University Federico II of Naples), Hans Fischer Senior Fellow | Artem Sevastopolsky (TUM), Doctoral Candidate | Host: Prof. Matthias Nießner (TUM)
Thanks to the rapid progress in AI-generated media, creating false images and videos with a high level of realism has become very easy. Coupled with ubiquitous social networks, this allows for the viral dissemination of fake news and raises serious concerns about the trustworthiness of digital content in our society. Traditional methods for verifying data authenticity are typically supervised and require very large training datasets that include both real and fake samples. A main issue is that new methods for generating synthetic data are proposed by the day, and such approaches cannot generalize to new generative models not included in the training set.
The goal of this project is to fill this gap and propose an approach that ensures generalization. Instead of relying on labeled real and fake data, we use only pristine samples, treating manipulations as anomalies relative to a learned model that captures the natural statistics of real-world imagery. Our collaborative efforts have focused on the following areas: detecting facial manipulations in videos, including face generation and recognition, as well as identifying AI-generated content in images.
To advance research in this field, we have been organizing a Workshop on Media Forensics at CVPR since 2021. The workshop has been a successful event and gave us the possibility to bring together researchers, foster collaboration, and benchmark progress in deepfake detection.
Identity-based deepfake video detection
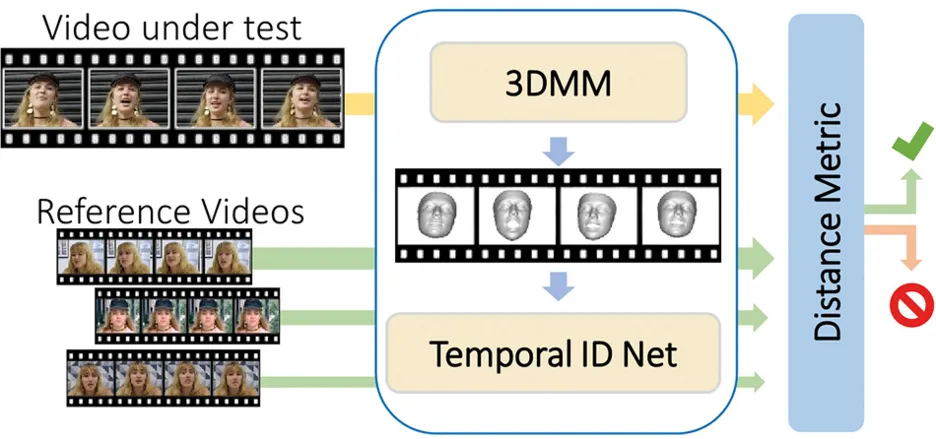
Our key insight is that each person has specific characteristics that a synthetic generator likely cannot reproduce. Hence, the approach focuses on learning an individual's biometrics, particularly their unique facial motion patterns, to detect potential inconsistencies. This represents a paradigm shift from traditional supervised methods. Instead of addressing the problem “Is this video real or fake?” our goal is to answer the question “Is this the person they claim to be?” – thus emphasizing person-specific verification. Being trained only on real videos, our method, called ID-Reveal [1] (Fig. 1), is independent of the specific type of manipulation. This work has been extended to deal with both audio and video [2], where we leverage a contrastive learning paradigm to learn the moving-face and audio segment embeddings that are most discriminative for each identity (see Fig. 2). Thanks to our multimodal approach, we can detect manipulations in both video-only and speech-only data, as happened when investigating realistic cases involving known individuals [3].
Figure 1
AI-generated image detection
To identify fully and locally AI-manipulated content in generic images, we rely on low-level traces, which are invisible forensic artifacts embedded in the image. We extract a learned noise-sensitive fingerprint (Noiseprint++) that bears traces of in-camera processing steps [4]. When images are manipulated, these telltale traces may be corrupted, an event that, if detected, allows one to carry out powerful forensic analyses. This is trained in a self-supervised manner using only pristine images taken from more than 1,000 different camera models. The scientific and practical impact of this work is evident from the fact that the technique has already been integrated into the Image Verification Assistant tool [5], which is used by journalists for fact-checking.
We have proposed an alternative strategy for fully generated image detection that is again based on an accurate statistical model of the real class [6]. Our key idea is to use a lossless coder to learn a reliable statistical model of real images. Lossless coding is a mature field of research based on sound information-theoretic concepts. Most image lossless coders work by predicting the value of each pixel based on a suitable known context and then encoding the prediction error. If the image is real, it follows the intrinsic statistical model of real images, and its pixels are not too surprising for the encoder. On the contrary, the pixels of synthetic images happen to exhibit unexpected values, thereby causing a coding cost larger than expected.
Figure 2
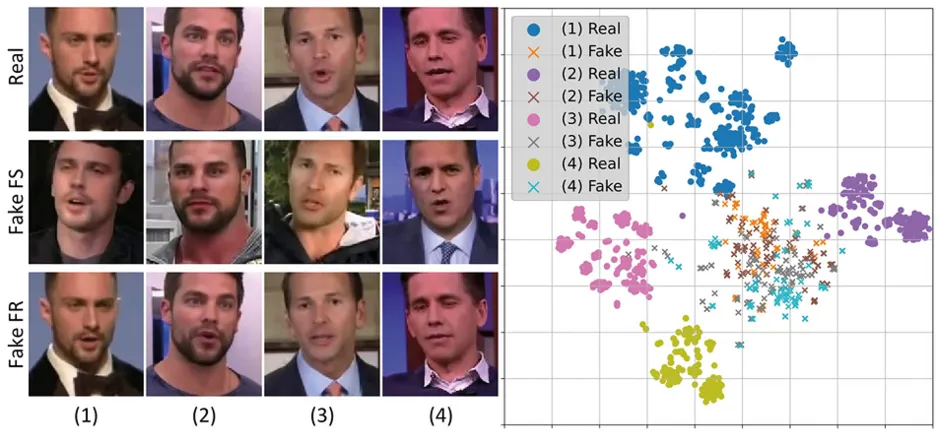
generally distant from their real counterparts. Image: Cozzolino, D. Pianese, A., Nießner, M. & Verdoliva, L. Audio-Visual Person-of-Interest DeepFake Detection. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 943-952 (2023).
TUM-IAS doctoral candidate research
The TUM-IAS supported the doctoral candidate Artem Sevastopolsky in this project. The research initially focused on enhancing facial recognition, while also releasing two training datasets for unsupervised pretraining and a large-scale protocol for bias estimation [7]. Additionally, we developed a generative model for 3-D human heads that combines flexible animation with high detail preservation [8]. The collaboration has resulted in a paper accepted at ICCV 2023 and another scheduled for presentation at 3DV 2025.
Future research
There is still much room for research in this field, and there are many aspects that deserve deeper investigation. Below, we highlight a few key directions for future investigation.
Intent characterization: The boundary between real and fake is blurring as AI becomes commonplace for tasks such as compression and enhancement. In the near future, when generative AI will be everywhere, should we still call these images fake? Instead, the focus should shift to characterize the intent behind media, whether real or AI-generated.
Explainability: Similarly, understanding the meaning of AI-generated images in relation to their context will allow us to make sound decisions about their harmful potential. More generally, being able to provide an interpretation of the score provided by the detector would help to make more convincing decisions.
Robustness to adversarial attacks: Although there are research studies that analyze the performance of detectors in the presence of adversarial attacks, only a few detectors are designed with the aim of withstanding such attacks.
Active methods: In recent years, research has focused mainly on passive methods, but modern active approaches offer valuable tools to enhance forensic capabilities. Some embed invisible watermarks to certify authenticity, while others insert imperceptible signals to disrupt editing tools and prevent malicious use.
Figure 3
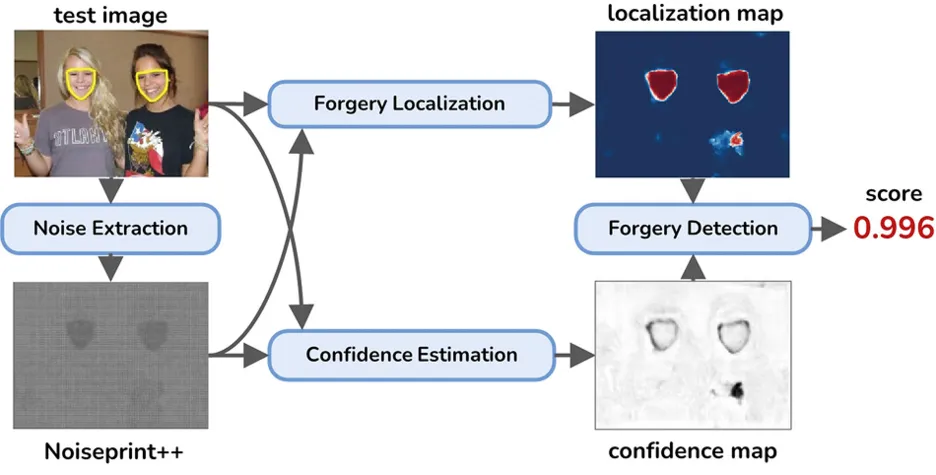
Vision and Pattern Recognition (CVPR), 20606–20615 (2023).
[1]
Cozzolino, D., Rössler A., Thies, J., Nießner M. & Verdoliva, L. ID-Reveal: Identityaware DeepFake Video Detection. IEEE/CVF International Conference on Computer Vision (ICCV), 15108-
15117 (2021).
[2]
Cozzolino, D., Pianese, A., Nießner, M. & Verdoliva, L. Audio-Visual Person-of-Interest DeepFake Detection. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 943-952 (2023).
[3]
www.restofworld.org/2023/indian-politician-leaked-audio-ai-deepfake
[4]
Guillaro, F., Cozzolino, D., Sud, A., Dufour, N. & Verdoliva, L. (2023).
[5]
https://mever.iti.gr/forensics
[6]
Cozzolino, D., Poggi, G., Nießner, M. & Verdoliva, L. (2024).
[7]
Sevastopolsky, A., Malkov, Y., Durasov, N., Verdoliva, L. & Nießner, M. (2023).
[8]
Sevastopolsky, A. et al. (2025).
Selected publications
- Cozzolino, D., Rössler A., Thies, J., Nießner M. & Verdoliva, L. ID-Reveal: Identity-aware DeepFake Video Detection. IEEE/CVF International Conference on Computer Vision (ICCV), 15108–15117 (2021).
- Sevastopolsky, A., Malkov, Y., Durasov, N., Verdoliva, L. & Nießner, M. How to boost face recognition with StyleGAN? IEEE/CVF International Conference on Computer Vision (ICCV). 20924–20934 (2023).
- Guillaro, F., Cozzolino, D., Sud, A., Dufour, N. & Verdoliva, L. TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20606–20615 (2023).
- Cozzolino, D., Poggi, G., Nießner, M. & Verdoliva, L. Zero-Shot Detection of AI-Generated Images. European Conference on Computer Vision (ECCV), 54–72 (2024).
- Sevastopolsky, A. et al. HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs. International Conference on 3D Vision (3DV) (2025).