Data-driven flow capture and reconstruction
The Focus Group devised data-driven techniques for reconstructing 3-D motion in flows using sparse and single-view video inputs. Our approach introduces a global transport formulation, establishing a connection between real-world capture data and a differentiable physics solver. We conducted training for neural networks to infer 3-D motion from monocular videos in the absence of 3-D reference data.

Focus Group: Simulation and Digital Twin
Prof. Barbara Solenthaler (ETH Zurich), Alumna Hans Fischer Fellow (funded by the Siemens AG) | Erik Franz (TUM), Doctoral Candidate | Host: Prof. Nils Thürey (TUM)
The Simulation and Digital Twin Focus Group conducted research on fluid capture and the comprehensive description of flow dynamics. Traditional fluid capture methods often entail intricate hardware configurations and calibration procedures, creating a demand for simpler systems. An example is the video-based flow capture stage developed within Thürey’s research group at TUM. Estimating motion from input videos presents a formidable challenge due to motion being a secondary quantity, indirectly derived from changes observed in transported markers such as density. Unlike the single-step estimation in optical flow, motion estimation typically involves multiple interconnected steps to achieve stable global transport. Additionally, in this context, the volume distribution of markers is usually unknown and requires concurrent reconstruction during motion estimation.
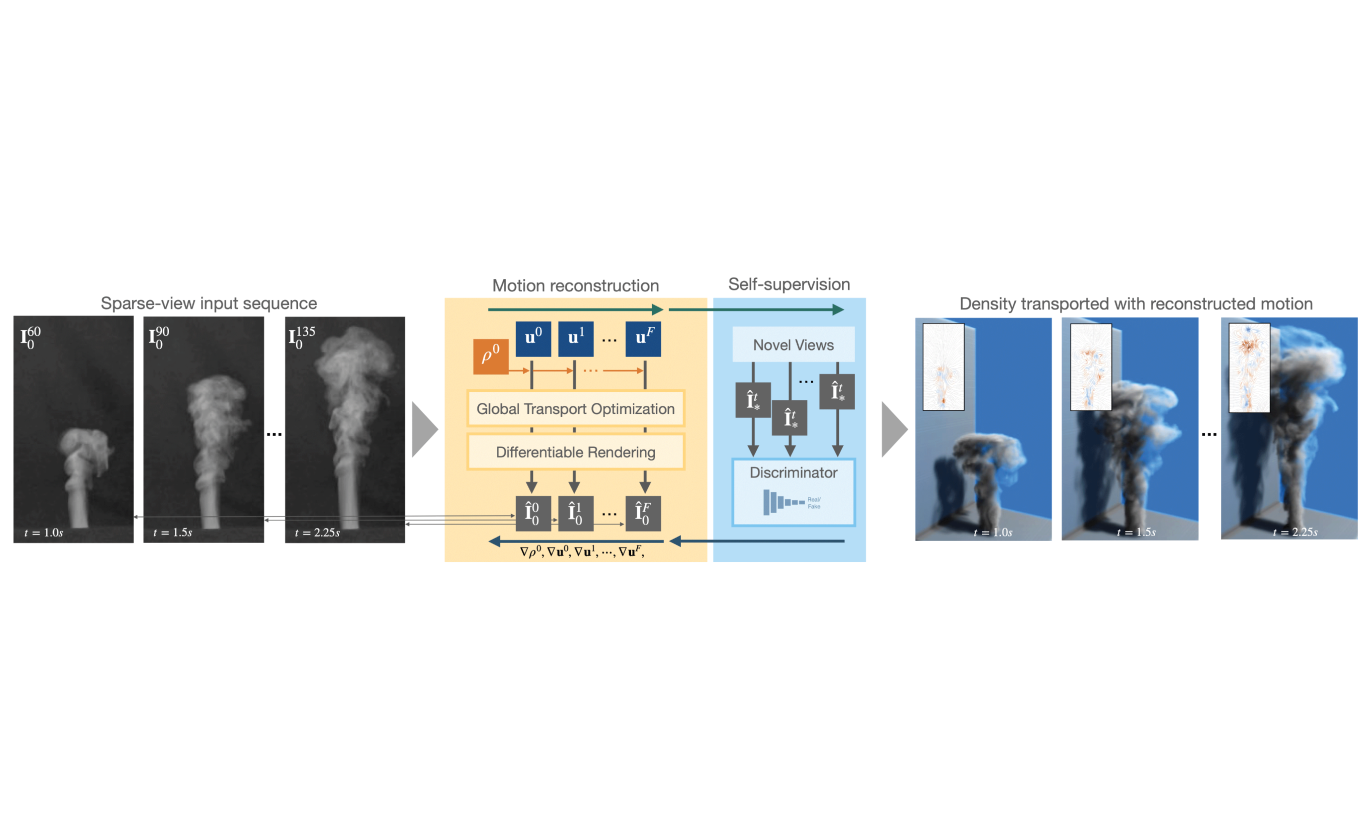
In our TUM-IAS project, we utilized a high-resolution dataset acquired through Thürey’s multi-view capture setup for precise tomography reconstructions. In the initial phase of the project, we integrated real-world captured data into a differentiable physics solver and employed optimization techniques to reconstruct volumetric flows from sparse views, employing a global transport formulation. Rather than deriving the space-time function of observations, our approach reconstructs motion on the basis of a single initial state. Additionally, we introduced a learned self-supervision mechanism, which imposes constraints on observations from unseen angles. These visual constraints are interconnected through transport constraints and a differentiable rendering step, resulting in a robust end-to-end reconstruction algorithm (Fig. 1). This enables the reconstruction of highly realistic flow motions, even from a single input view. Through a range of synthetic and real flow scenarios, we demonstrated that our proposed global reconstruction of the transport process significantly enhances the reconstruction of fluid motion.
Figure 1
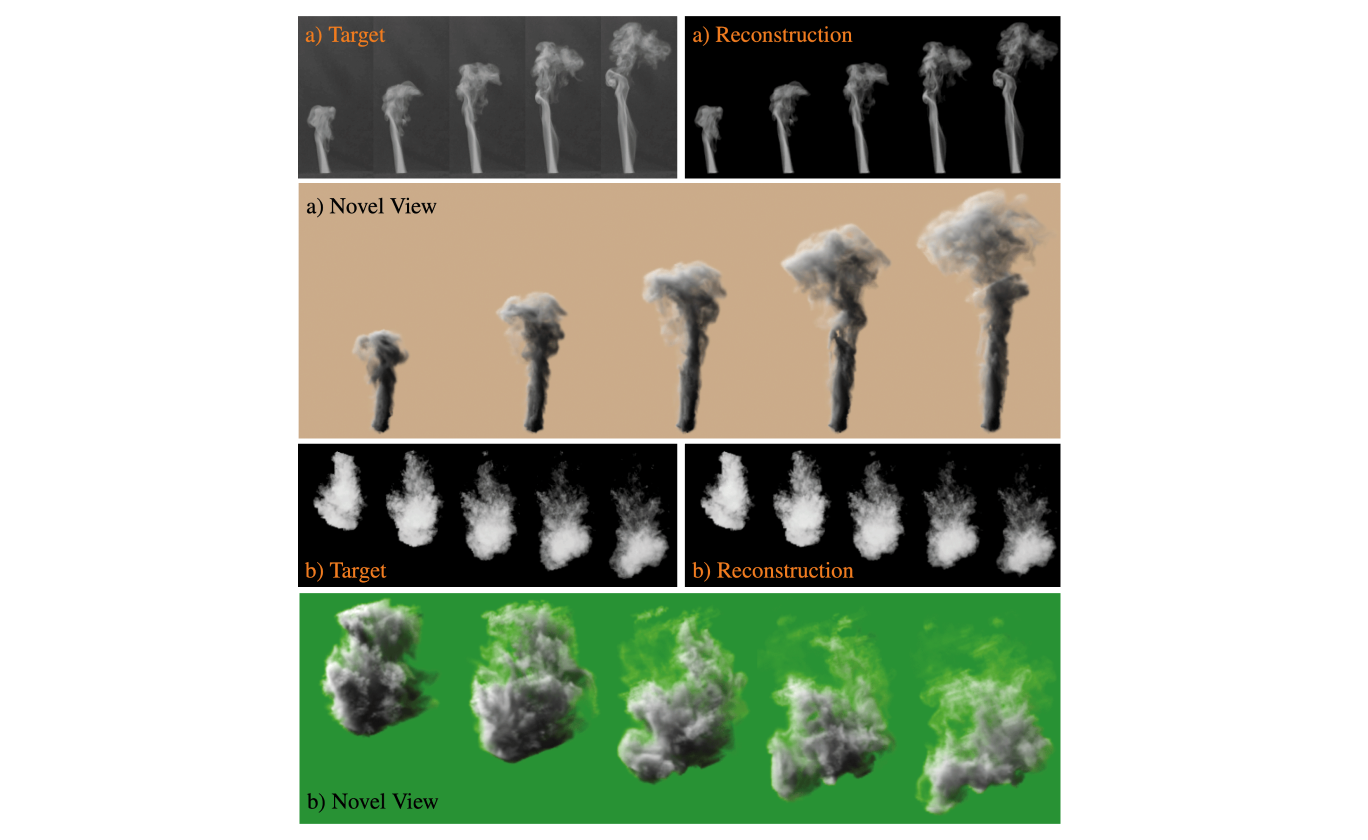
We observed a notable interest in single-view motion estimation, achieved by incorporating physical priors in the form of governing equations. However, despite robust priors, dealing with the fully unconstrained depth dimension in a single viewpoint remains a challenge. In the latter part of the project, we introduced a deep learning-based approach where a neural network learns to represent underlying motion structures. This allows almost instantaneous, single-pass motion inference without relying on ground truth motion data – a crucial aspect, especially for complex volumetric motions where direct acquisition of reference motions is impractical. Addressing the challenge of training neural networks to infer 3-D motions from monocular videos without available 3-D reference data, we employed an unsupervised training approach using observations from real-world capture setups. This involved generating an initial prototype volume, which is then moved and transported over time without volumetric supervision. Our method relies solely on image-based losses, an adversarial discriminator network, and regularization. It demonstrates the ability to estimate stable long-term sequences, closely matching targets for inputs such as rising smoke plumes (Fig. 2).
A current limitation in our methods is their exclusive support for white smoke, necessitating an extension of the rendering model for scenarios involving anisotropic scattering, self-illumination, or alternative materials. Additionally, our transport model relies on advection without obstructions, suggesting the potential for extensions to accommodate obstacles or multi-phase flows. To enhance long-term stability further, the method could be expanded to convey information about future time steps, offering improved guidance.
In summary, our TUM-IAS project successfully achieved its initial objective of bridging real-world flow-captured data with physics simulations through deep learning methods, facilitating a high-quality mapping between diverse data sources. Notably, we demonstrated that our networks can be effectively trained with single-view data and short time horizons, maintaining stability for extended sequences during inference. The resulting global trajectories from the neural global transport are both qualitatively and quantitatively competitive with single-scene optimization methods that demand significantly longer runtimes. This establishes our approach as a crucial factor for practical translation.
Figure 2
Selected publications
- Franz, E., Solenthaler, B. & Thürey, N. Learning to Estimate Single-View Volumetric Flow Motions without 3-D Supervision. International Conference on Learning Representations (ICLR) (2023).
- Franz, E., Solenthaler, B. & Thürey, N. Global Transport for Fluid Reconstruction with Learned Self-Supervision. Conference on Computer Vision and Pattern Recognition (CVPR) (2021).
- Wiewel, S., Kim, B., Azevedo, V.C., Solenthaler, B. & Thürey, N. Latent Space Subdivision: Stable and Controllable Time Predictions for Fluid Flow. Computer Graphics Forum 39(8), 15-25 (2020).
- Kim, B., Azevedo, V.C., Thürey, N., Kim, T., Gross, M. & Solenthaler, B. Deep Fluids: A Generative Network for Parameterized Fluid Simulations. Computer Graphics Forum 38(2), 59-70 (2019).
- Tang, J., Kim, B., Azevedo, V.C. & Solenthaler, B. Physics-Informed Neural Corrector for Deformation-based Fluid Control. Computer Graphics Forum 42(2), 161-173 (2023).